垂直切分就是要把表按模块划分到不同数据库中,这样的拆分在大型站点的演变过程中是非经常见的。当一个站点还在非常小的时候,仅仅有小量的人来开发和维护。各模块和表都在一起,当站点不断丰富和壮大的时候。也会变成多个子系统来支撑,这时就有按模块和功能把表划分出来的需求。例如以下图所看到的:
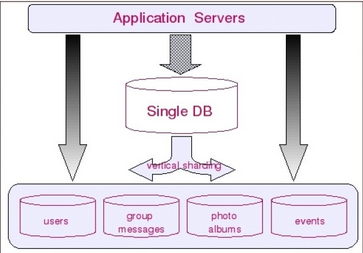
事实上,相对于垂直切分更进一步的是服务化改造。说得简单就是要把原来强耦合的系统拆分成多个弱耦合的服务,通过服务间的调用来满足业务需求看,因此表拆出来后要通过服务的形式暴露出去,而不是直接调用不同模块的表,淘宝在架构不断演变过程。最重要的一环就是服务化改造,把用户、交易、店铺、宝贝这些核心的概念抽取成独立的服务,也很有利于进行局部的优化和治理。保障核心模块的稳定性。这样一种拆分方式也是有代价的:
- 表关联无法在数据库层面做
- 单表大数据量依旧存在性能瓶颈
- 事务保证比較复杂
- 应用端的复杂性添加
上面这些问题是显而易见的,处理这些的关键在于怎样解除不同模块间的耦合性,这说是技术问题。事实上更是业务的设计问题,仅仅有在业务上是松耦合的,才可能在技术设计上隔离开来。
没有耦合性,也就不存在表关联和事务的需求。
另外,大数据瓶颈问题能够採用水平切分。
二、对数据库表的字段訪问比較均衡,业务导向不明显(对单一应用的高并发訪问)

水平切分没有破坏表之间的联系,全然能够把有关系的表放在一个库里。这样就不影响应用端的业务需求,而且这种切分能从根本上解决大数据量的问题。它的问题也是非常明显的:
- 当切分规则复杂时,添加了应用端调用的难度
- 数据维护难度比較大,当拆分规则有变化时,须要对数据进行迁移
对于第一个问题,能够參考怎样整合应用端和数据库端。
对于第二个问题能够參考一致性hash的算法,通过某些映射策略来减少数据维护的成本
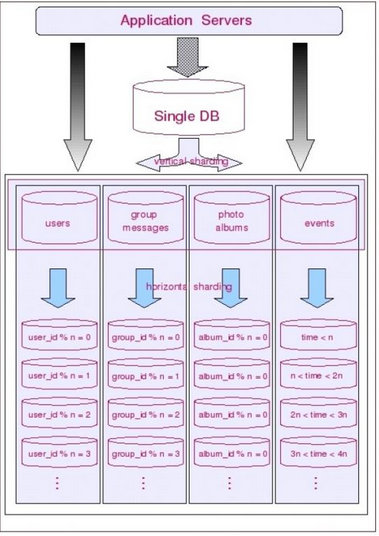
2)当然还能够把水平切分和垂直切分结合起来
由上面可知垂直切分能更清晰化模块划分,区分治理,水平切分能解决大数据量性能瓶颈问题。因此经常就会把两者结合使用,这在大型站点里是种常见的策略。这能够结合两者的长处,当然缺点就是比較复杂,成本较高,不太适合小型站点,以下是结合前面两个样例的情况:
三、对数据库表的单一字段訪问比較集中(秒杀、大量用户对同一账户操作)
对于这样的情况有非常多种解决方式。可是每一种都不是非常完美:
1)採用内存缓存或者缓存数据库来缓解数据的库的压力
详细做法是:在利用内存缓存或者缓存数据库把后台数据库server上相关的表数据载入到内存中,所用用户高并发的对内存数据进行处理,然后再定时轮询的方式把内存的数据刷新到后台数据库表中,这样的做法有下面问题:
a)不能非常好保持内存数据与数据库数据的一致性。
b)假设出现断电、内存损坏等情况,会有数据丢失;
2)採用对数据库表水平切分。然后在后台的程序中对各个表的数据总体控制
比如,有10000亿人民币为1亿人并发提供贷款业务。
在数据库中建立一个总表存下10000亿人民币,然后再建立10张分表。初始设为空;后台java程序在訪问数据库时会有一个控制程序(中间件),开10个 线程池。每一个线程池相应一个数据库分表,其中间件接受到贷款申请时,中间件就会依据用户的ID(能够ip地址,账户编号)hash到相应的线程去到总表中借款,这个借款数目能够依据总表的资金和用户的要借的资金去申请额度(比方用户申请10w,总表有1000亿,相应线程能够向总表申请10亿),存入相应分表。供这个用户提供贷款,假设再有下个用户再到此线程池操作数据库表,就直接操作。分表中金额不够的时候再到总表中借款。
这种设计攻克了,高并发存储数据库的问题,可是添加了后台的程序设计的难度,加大了程序的耦合度。
3)採用“记流水不记账“的方式应对
还用上一个样例,这样的方式。须要在数据库中设计两个表,一个用来存储账户金额(账户表),还有一个记录”流水“(流水表), 所谓”记流水“是指每当有个请求到来,就向流水表中插入一条记录。然后定时对所插入的记录进行统计,update账户表的数据,当然这样的方式,须要在内存中添加变量,来控制所用用户的贷款不能超过所贷款的总金额。这样的处理方式是数据库端处理秒杀、高并发集中訪问数据库表字段的有效方式,使用比較广泛。
4)针对网购秒杀还有其针对性的设计。由于网购秒杀和高并发操作银行账户不同,网购秒杀同意用户请求丢失,简单的来说,仅仅须要在内存缓存或者内存数据库(充当队列)中保存较早的用户请求。然后再异步的处理这些请求来操作数据库(更新数据库)。